Nexa SDK
综合介绍
Nexa SDK是一个专业的模型部署工具包。它专注于将各类AI模型快速部署到不同设备上。这个工具包支持移动设备、个人电脑、汽车系统和物联网设备。它能够处理多种类型的AI模型,包括大语言模型、多模态模型、语音识别和语音合成模型。
该SDK特别注重部署效率和数据隐私保护。它已经在生产环境中经过充分测试,可以立即投入使用。它兼容多种硬件平台,包括神经处理单元、图形处理器和中央处理器。这使得开发者可以在不同性能的设备上灵活部署AI模型。
功能列表
- "跨平台部署" - 支持在移动设备、PC、汽车和物联网设备上运行
- "硬件优化" - 针对NPU、GPU和CPU进行专门优化
- "隐私保护" - 确保用户数据在本地处理,保护隐私安全
- "高效推理" - 提供快速的模型推理能力
- "生产就绪" - 生产环境开箱即用,无需额外配置
<li"多模型支持" - 兼容LLM、多模态、ASR和TTS等多种AI模型
使用帮助
要开始使用Nexa SDK,首先需要下载安装包。访问官方网站获取最新版本的SDK。根据你的开发环境选择对应的版本。支持Windows、Linux、macOS和移动操作系统。
安装过程很简单。解压下载的安装包到指定目录。然后设置环境变量。将SDK的bin目录添加到系统PATH中。这样就完成了基础安装。
项目配置
在你的项目中引入Nexa SDK。如果是C++项目,在CMakeLists.txt中添加依赖。如果是Python项目,使用pip安装对应的Python包。配置编译选项时,记得链接Nexa的核心库。
初始化SDK是重要的一步。创建配置对象,设置模型路径和设备类型。根据你的硬件选择最优的计算后端。NPU设备能提供最好的性能,GPU次之,CPU最通用。
模型部署
部署模型前需要先加载模型。调用loadModel函数,传入模型文件路径。SDK会自动检测模型类型并配置相应的推理引擎。支持ONNX、TensorRT等多种模型格式。
对于大语言模型,需要设置推理参数。包括最大生成长度、温度参数和重复惩罚等。合理的参数设置能提升生成质量。多模态模型需要配置图像和文本的预处理管道。
推理执行
创建推理会话对象。准备输入数据,根据模型要求进行预处理。调用run方法执行推理。获取输出结果后进行后处理。语音识别模型返回文本,语音合成模型返回音频数据。
内存管理很重要。大型模型会占用较多内存。及时释放不再使用的会话和缓冲区。使用流式处理可以降低内存峰值使用量。
性能优化
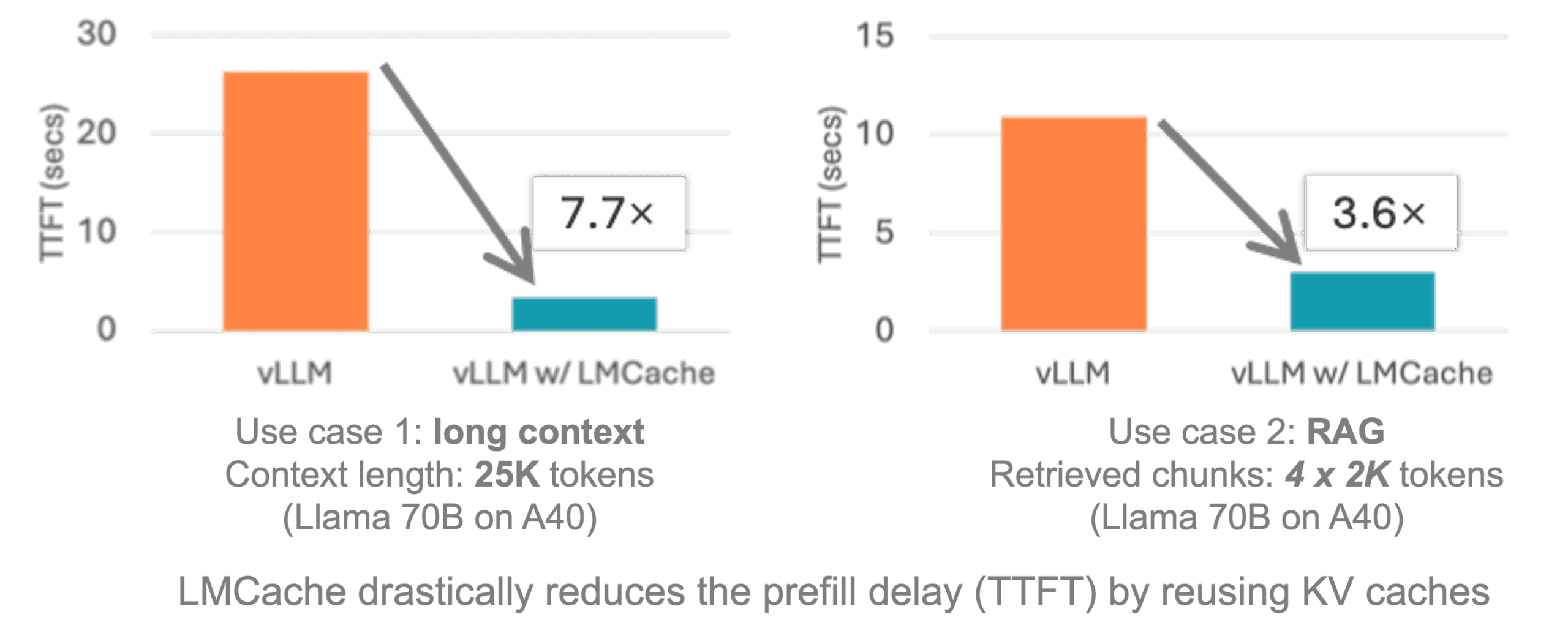
启用量化可以提升推理速度。8位量化能在精度损失很小的情况下大幅提升性能。对于移动设备,建议使用动态量化。PC和服务器可以使用静态量化获得更好效果。
批处理能提高吞吐量。将多个请求合并成一个批次处理。这对于服务端部署特别有用。设置合适的批处理大小,平衡延迟和吞吐量。
部署测试
在目标设备上测试部署效果。检查模型运行是否正常。验证输出结果的准确性。测试不同负载下的性能表现。确保在真实使用场景下稳定运行。
监控资源使用情况。关注内存占用、CPU利用率和推理延迟。根据监控数据调整配置参数。优化模型和推理设置,达到最佳性能。
产品特色
Nexa SDK能够在多种硬件平台上高效部署各类AI模型,确保数据隐私和生产环境稳定性。
适用人群
- 移动应用开发者:需要在手机等移动设备上集成AI功能的应用开发者
- 嵌入式系统工程师:在物联网设备和汽车系统中部署AI模型的工程师
- AI产品经理:负责将AI模型落地到实际产品中的管理人员
- 科研人员:需要在多种设备上验证和部署AI模型的研究人员
应用场景
- 智能助手应用:在手机和智能设备上部署语音助手和对话AI
- 车载智能系统:在汽车中集成语音控制和智能交互功能
- 工业物联网:在边缘设备上部署视觉检测和语音识别模型
- 隐私敏感应用:需要本地处理数据的医疗、金融等领域的AI应用
常见问题
- Nexa SDK支持哪些操作系统?
支持Android、iOS、Windows、Linux和多种嵌入式操作系统,覆盖大多数主流平台。 - 如何选择适合的计算后端?
根据设备硬件选择:NPU提供最佳性能,GPU平衡性能与通用性,CPU确保最大兼容性。 - 模型部署需要多少存储空间?
取决于模型大小,通常从几十MB到几个GB不等,支持模型压缩减小占用空间。 - 是否支持模型加密?
提供完整的模型加密解决方案,保护知识产权和商业机密。 - 如何获取技术支持?
通过官方文档、社区论坛和专业技术支持团队获得帮助,确保顺利部署。